This tutorial will walk through how to leverage the
tidyCDISC app’s Population Explorer tab. This module exists
to glean visual insights on patient populations via a diverse mix of
chart types, each uniquely designed to drill down deep into the data.
The Population Explorer tab will interface with all data types:
ADSL, BDS, OCCDS, and
TTE. This tutorial will use 5 CDISC Pilot data files: An
ADSL, ADVS, ADLBC,
ADAE, and the ADTTE.
Tab layout
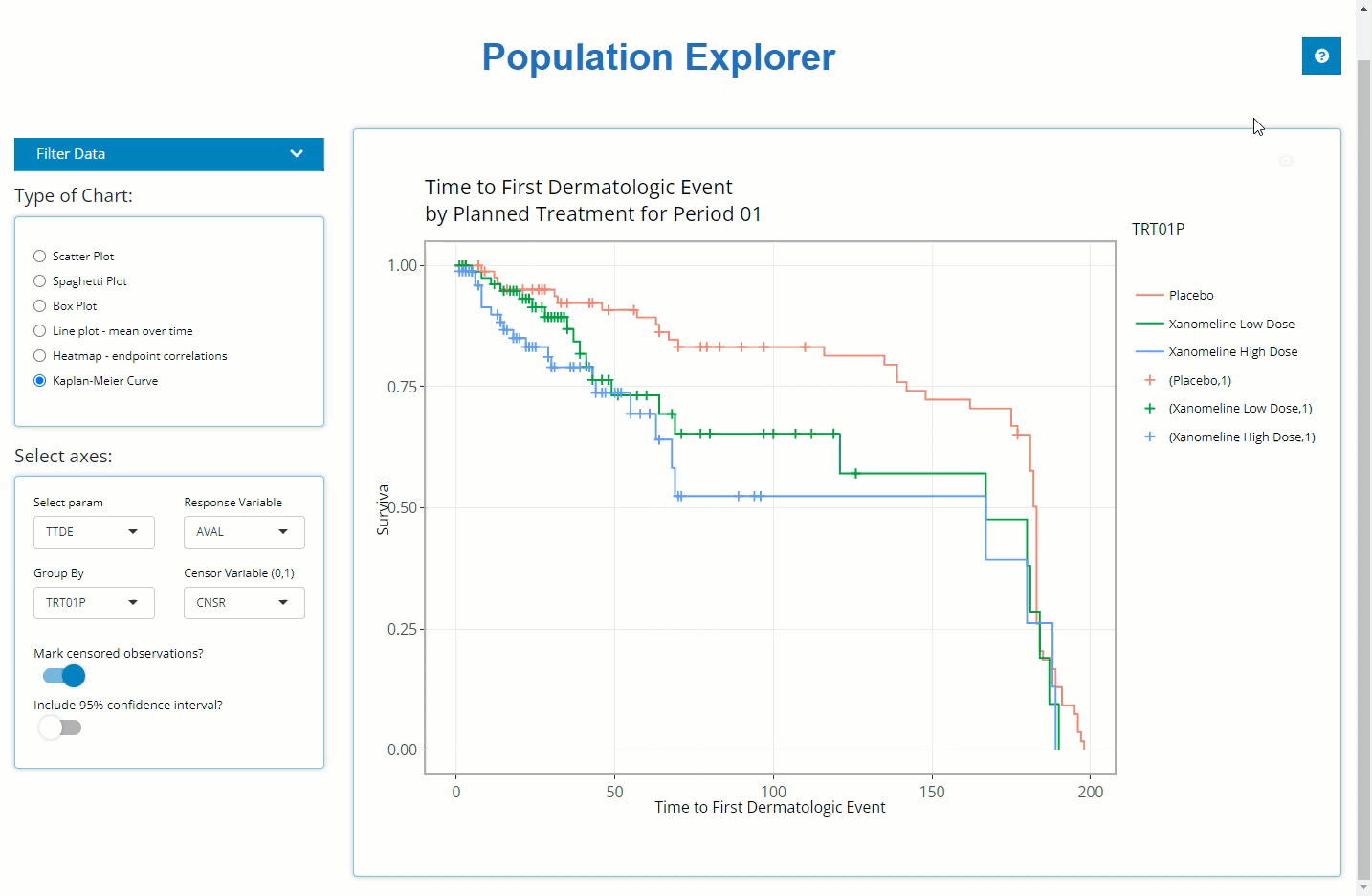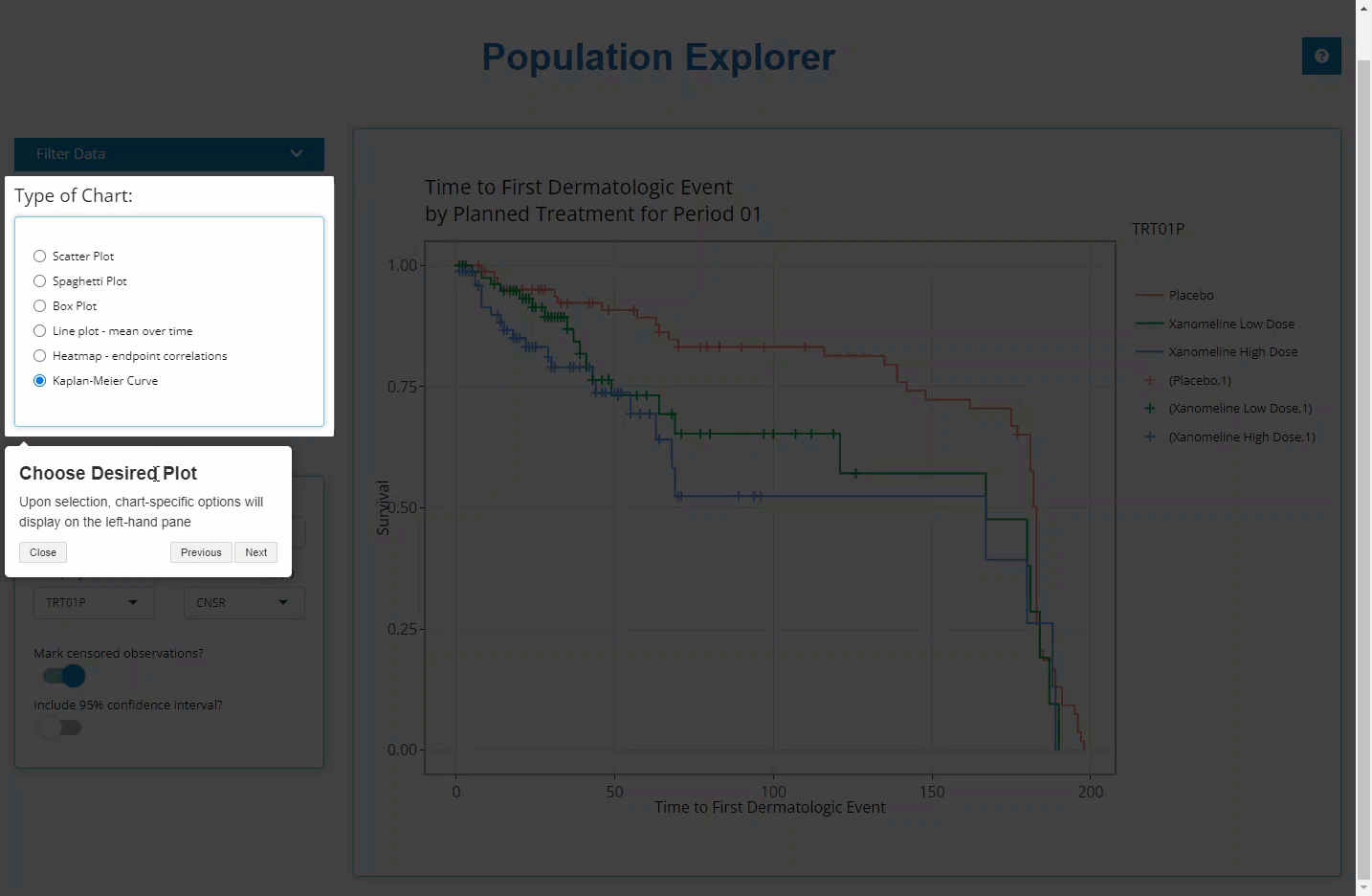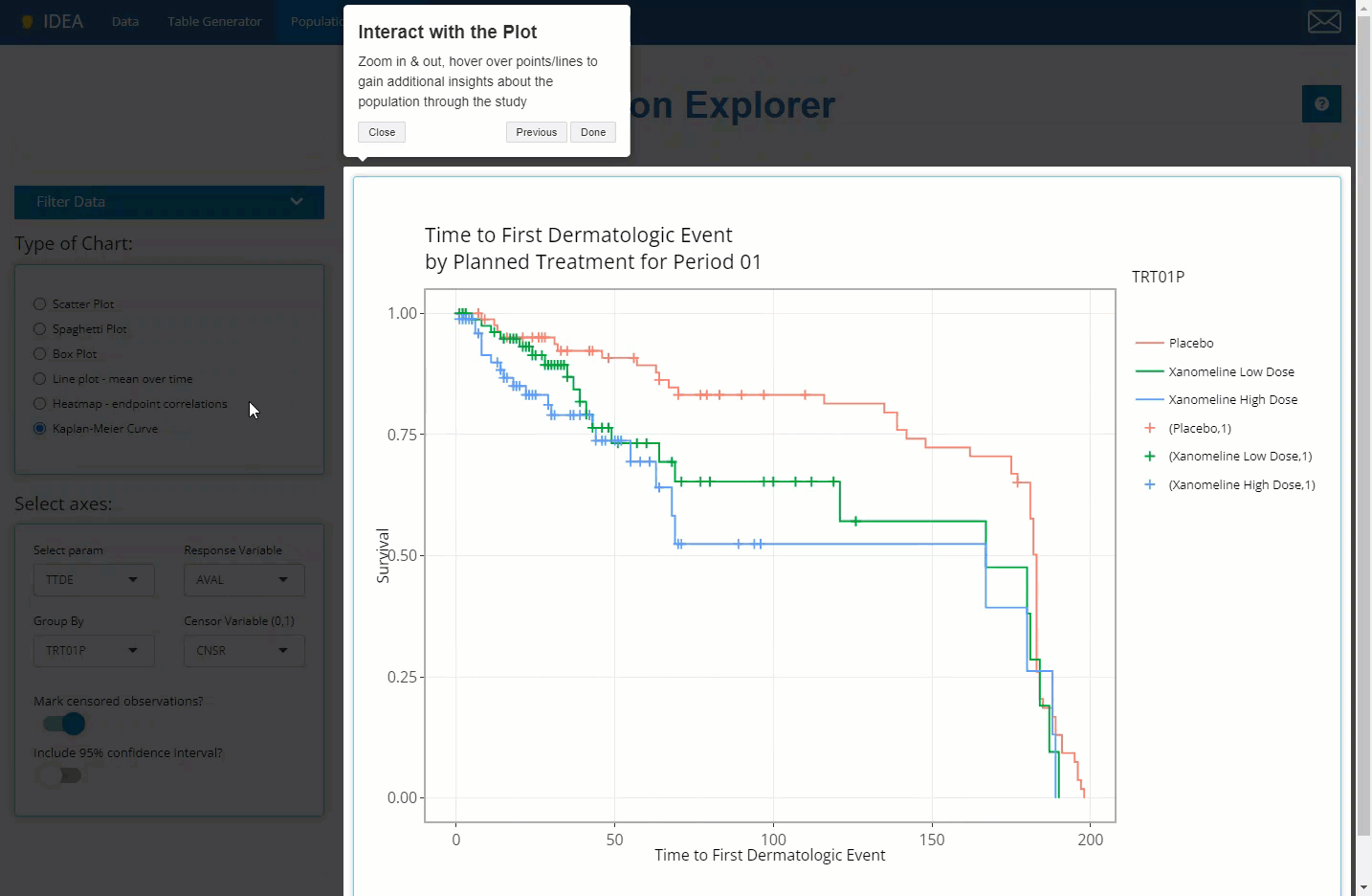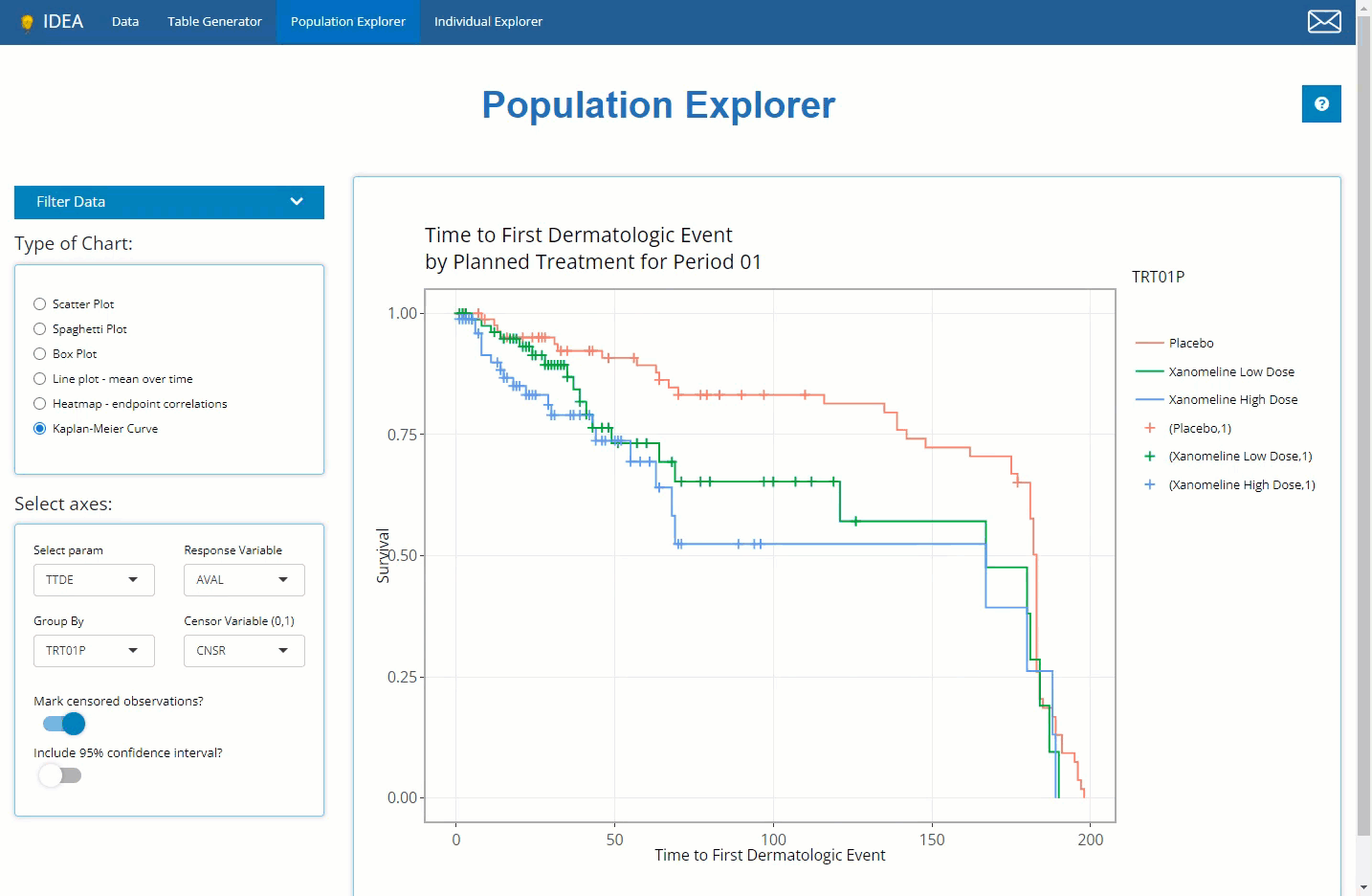
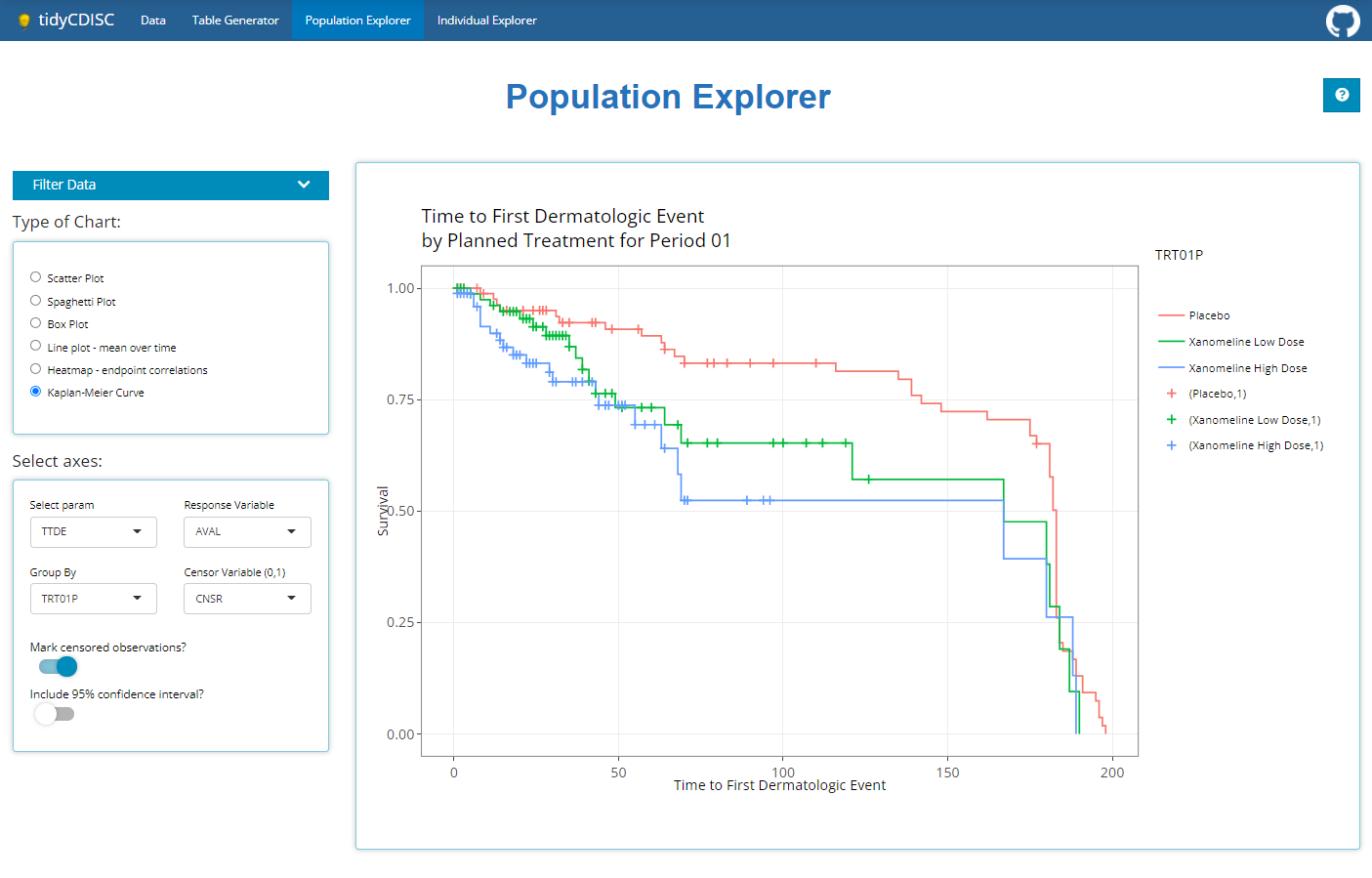
Below is a plot built with the population explorer, where an example Kaplan Meier curve is being rendered. There are 4 main components to this tab, the first 3 are located on the side panel:
The filter data widget (we’ll cover this last)
The type of chart selection
The plot controls
The desired plot
Together, we’ll take a look at each of element of the Population Explorer, including the chart types and their controls, plot options and interactivity.
Type of Chart
Below are the currently supported chart types, which can be expanded to include any additional charts. If you have an idea for a useful chart typically used for trial analysis, just send the developers a message with your request!

It’s important to note that the Kaplan-Meier Curve
option will not appear unless an ADaM of class TTE
(contains the CNSR variable) is uploaded on the Data tab.
All other chart types will display by default.
General plot controls
The user interface to each plot dynamically updates based on the
chart type selected. In general, you’ll be asked to specify how to set
up the axes using either variables or parameters from BDS
class data sources, among other options. Consistent with the Table
Generator, when a parameter is being plotted from a BDS
data source, the user will need to select which data points to plot:
“AVAL”, “CHG”, or “BASE” and possibly, a specific visit. The only
exception to this would be the “spaghetti” and “line plot - mean over
time” as the x-axis will always be display all visits of the time
variable you choose.
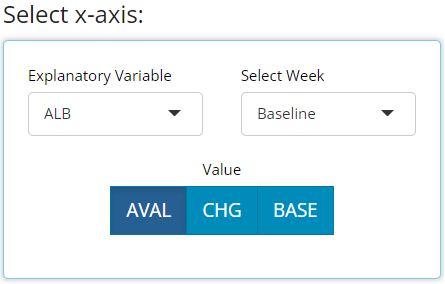
If a variable is chosen for plotting, the ‘AVAL’/‘CHG’/‘BASE’ options & visit selector will disappear:
Besides those general axes set up controls, the “scatter” and “line plot - mean over time” have some excellent “Group data” options in common (displayed below). In general, both drop down lists only contain character or factor variables.
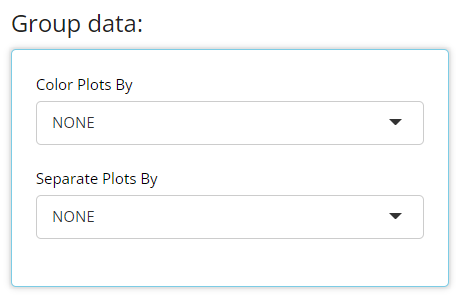
The “Color Plots By” variable helps the user create
a different colored line for a variable’s categories. In the example
below, here is a plot where “Color Plots By” is
NONE:
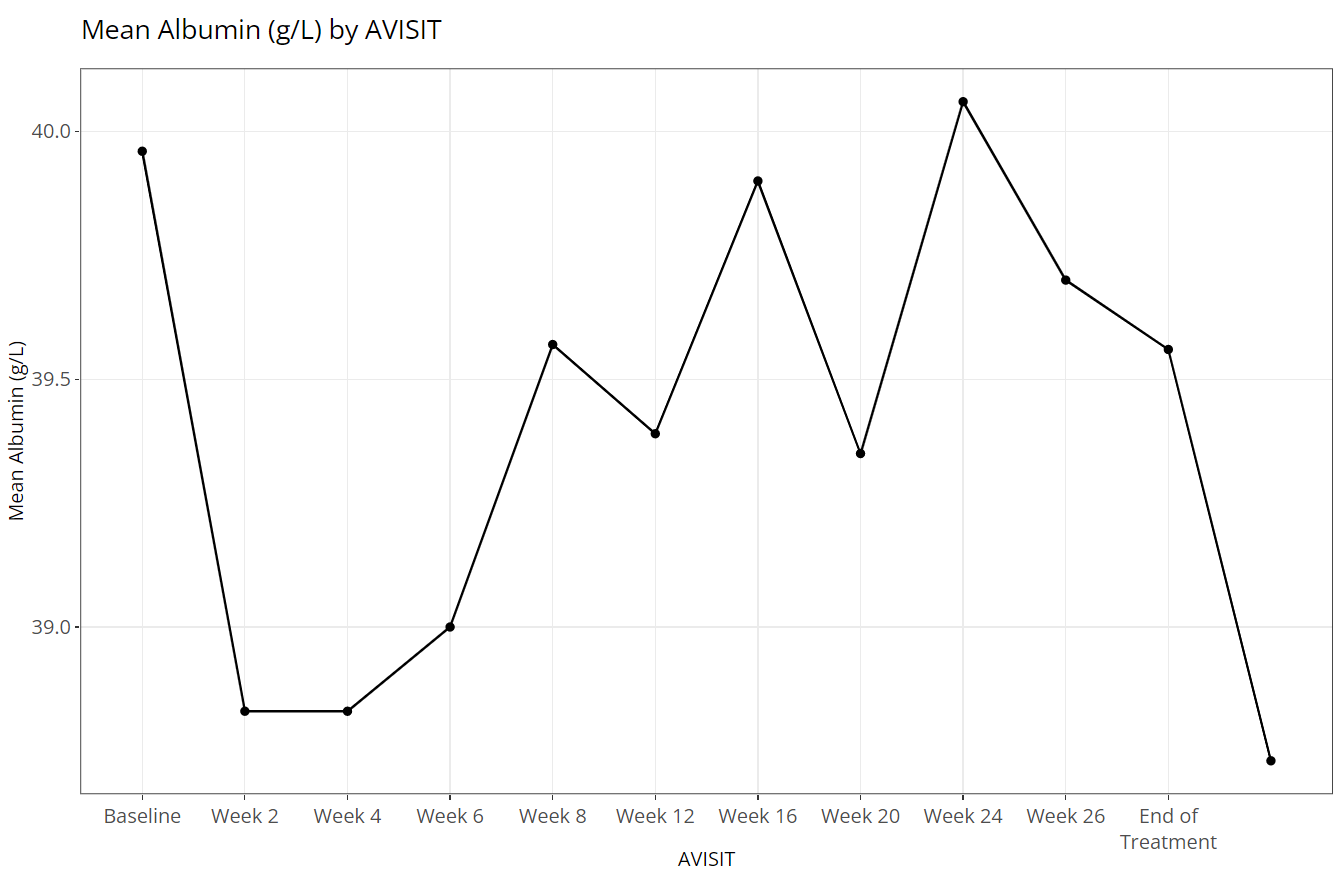
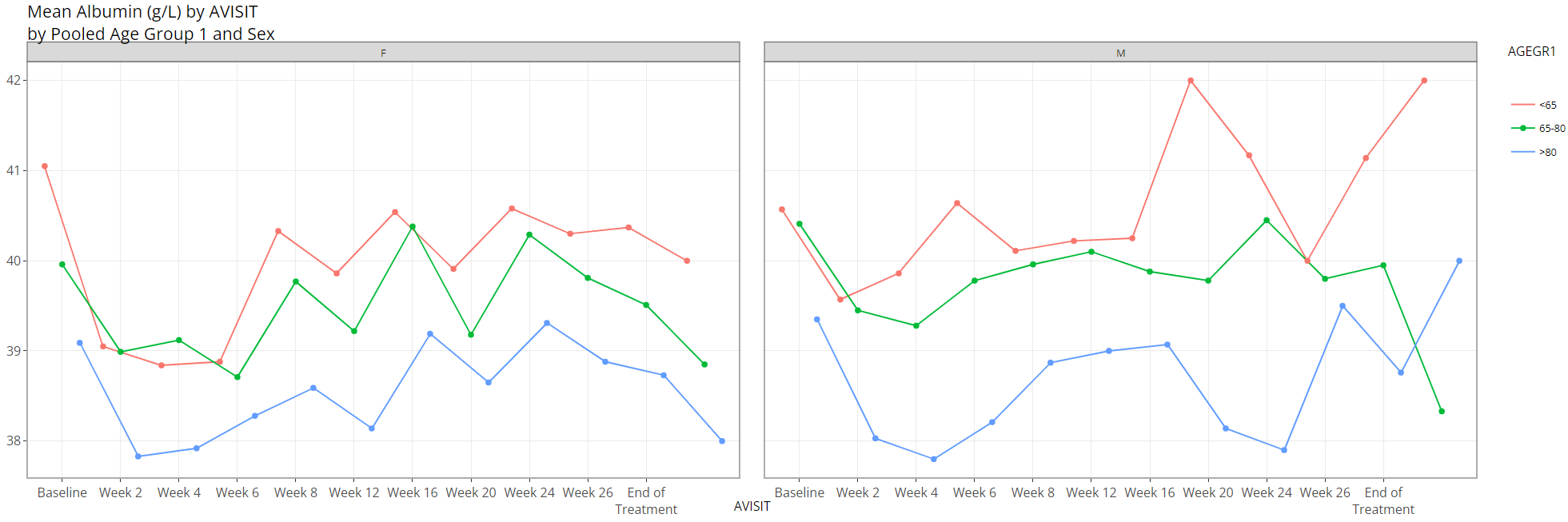
If we switch “Color Plots by” to from
NONE to AGEGR1, the application creates the
following line plot of means at each visit:
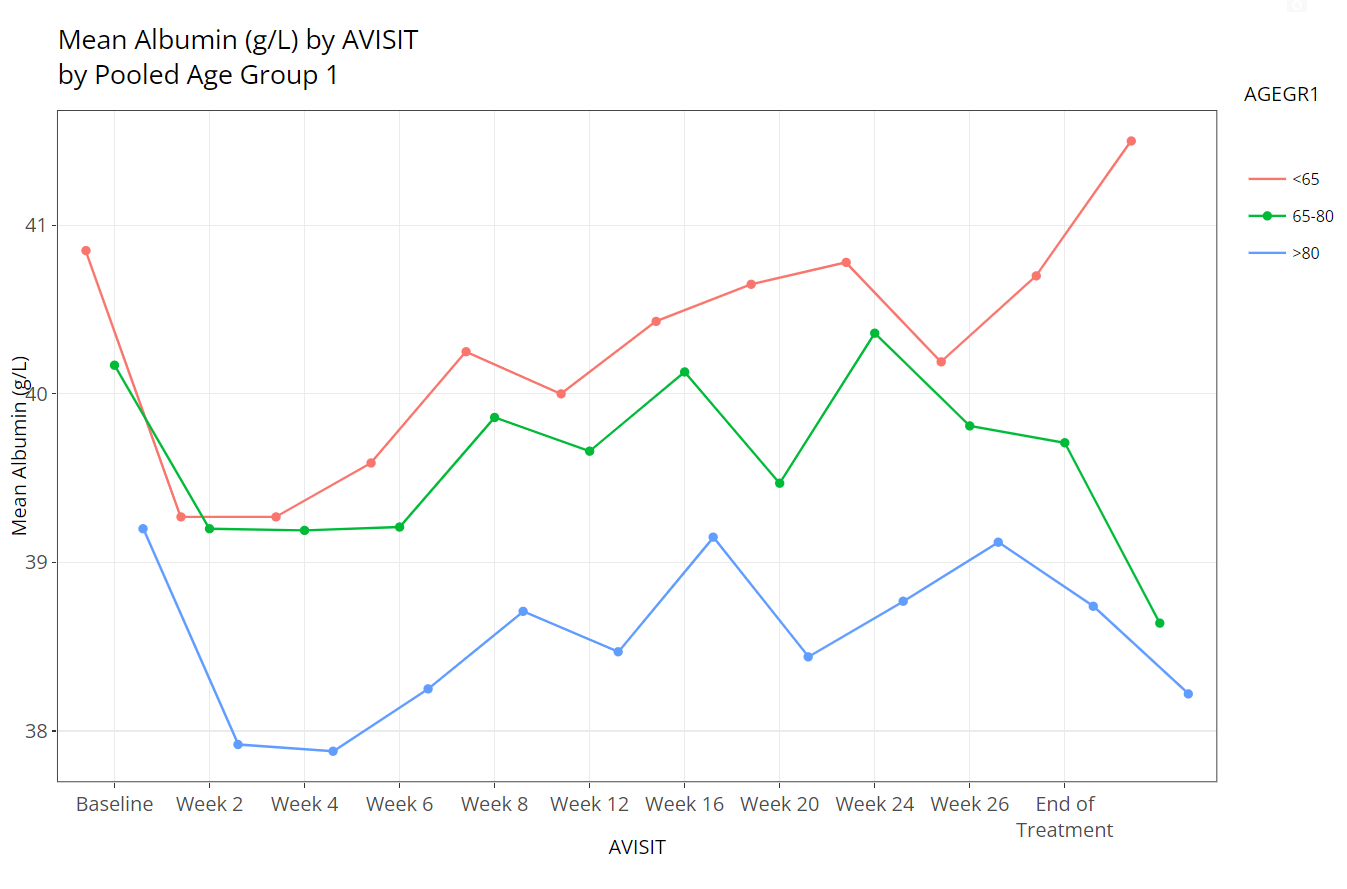
Similarly, if we leave “Color Plots By” as
NONE and change “Separate Plots By” to
TRT01P, the app creates a separate plot for each planned
treatment arm:
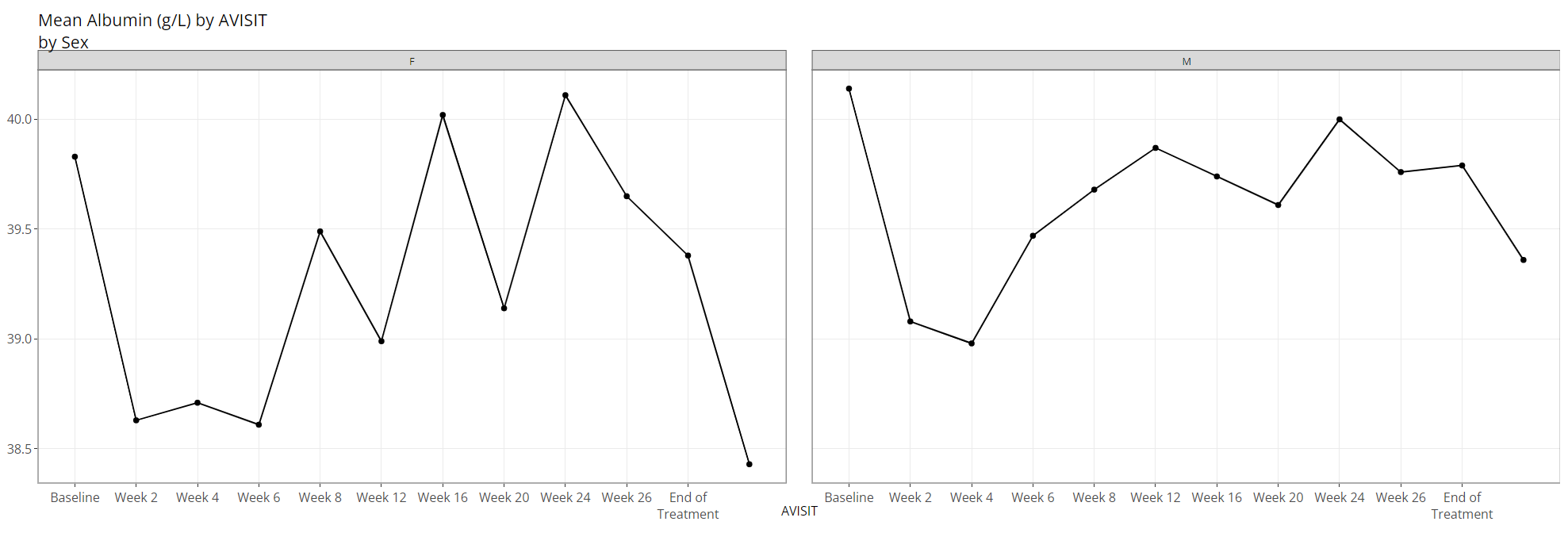
Lastly, the user can select a variable for both “Color Plots
By” and “Separate Plots By” to view a plotted
line for the combination of the selections’ levels: in this case
AGEGR1 has three levels and SEX has two, so
the end result is 2 x 3 = 6 plotted lines.
The plots
The plot is displayed prominently on the main panel, and embedded
with a host of interactive features when moused over. In the example
below, the “line plot - mean over time” contains additional information
available at each plotted point like the visit variable and visit value,
plus a slurry of statistics for the parameter selected (ALB
in this case): mean, standard error, standard deviation, and patient
count (N). Also notice the SEX variable is selected for
“Color Plot By”. Thus, when we hover, the info boxes
are color coordinated and include the chosen line’s SEX
value.
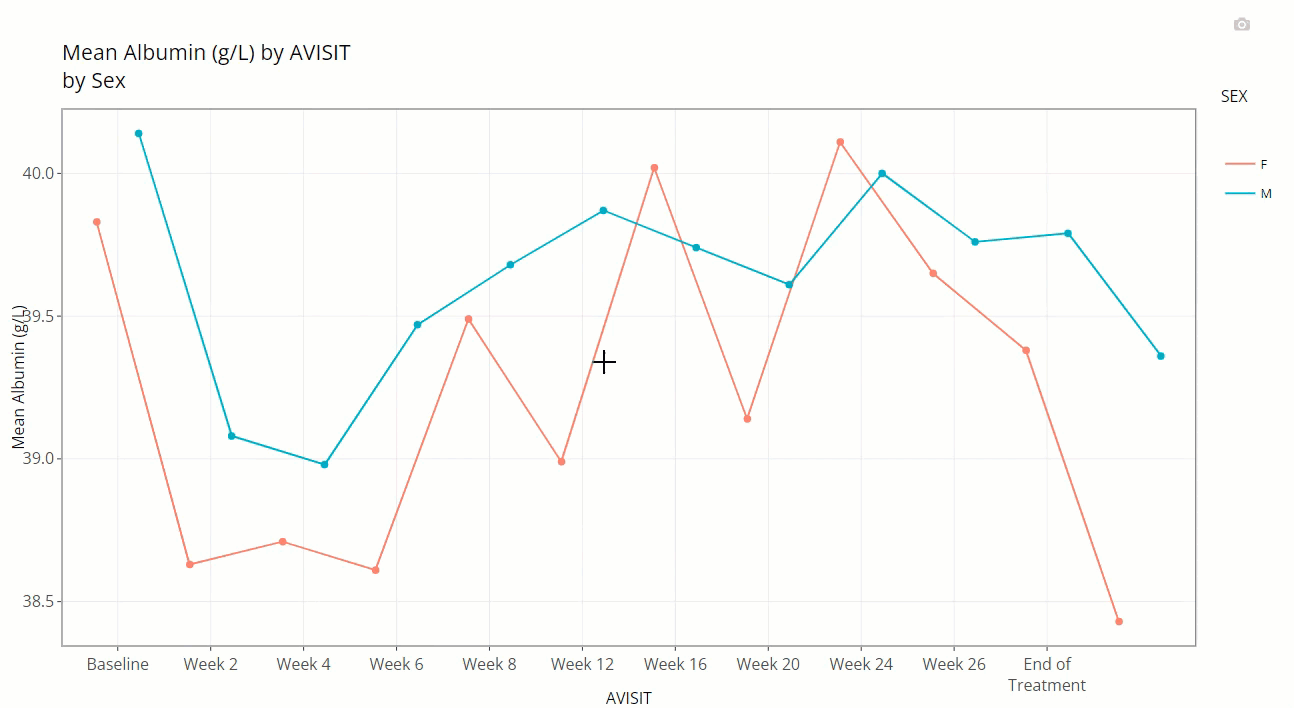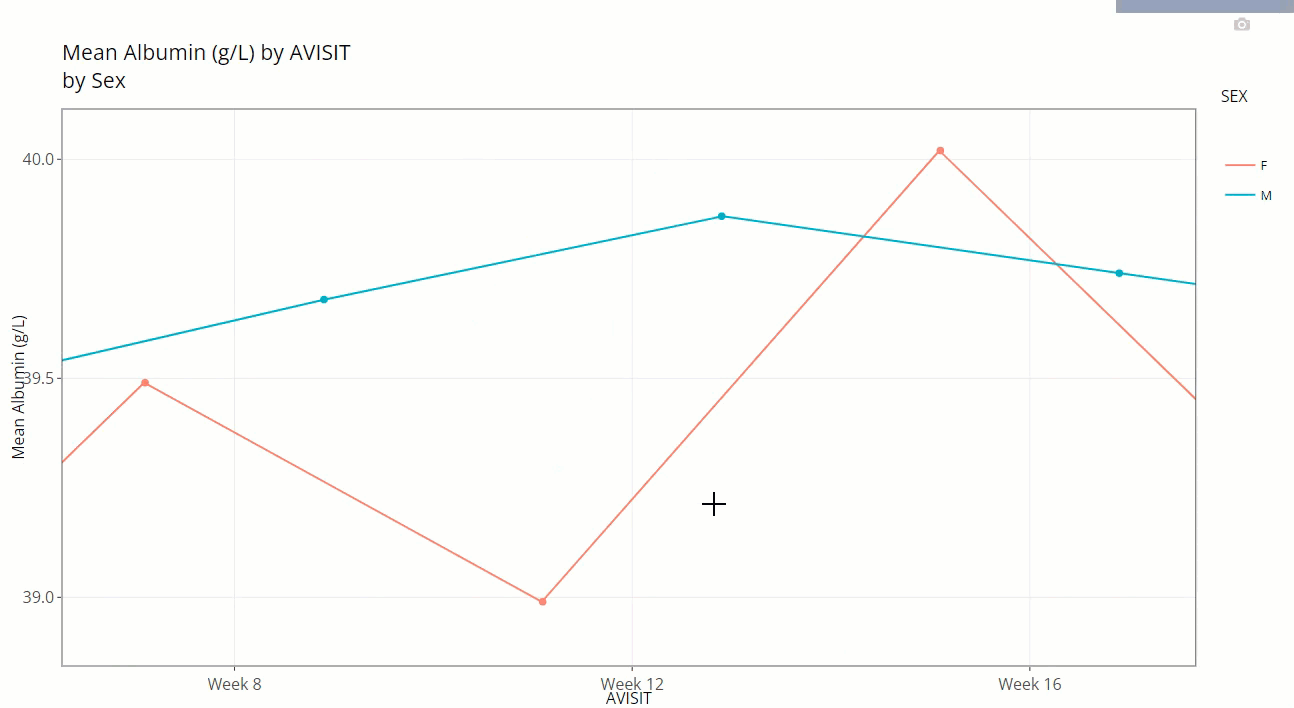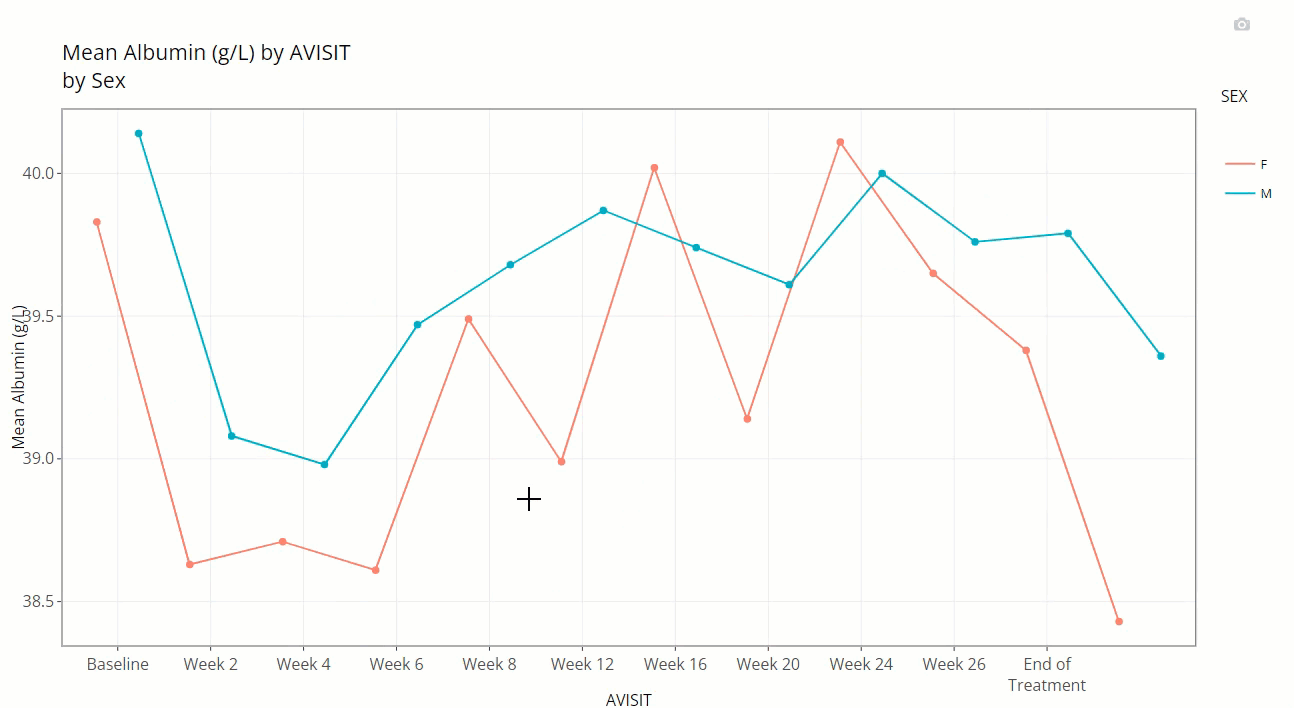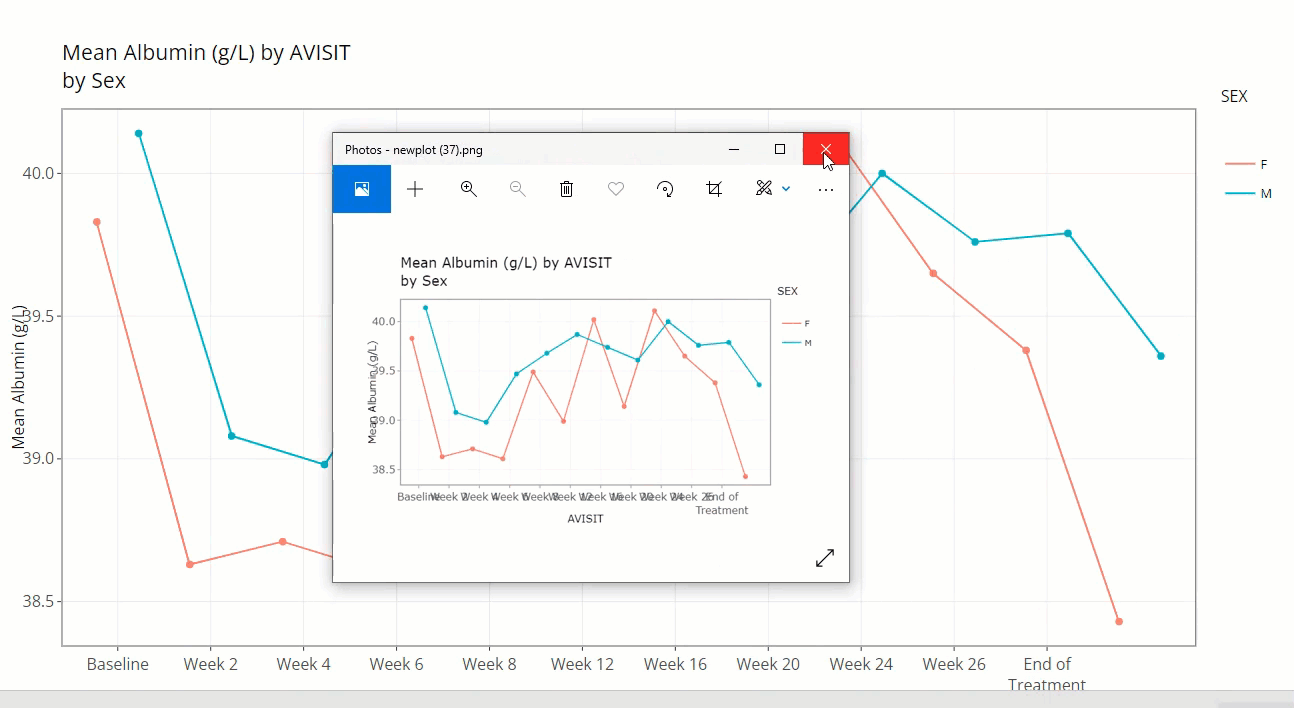
Notice how the user is also allowed to zoom-in / pan-out of any portion of the graph, retaining only the desired points. This can be helpful to filter out outliers and avoid using the “Filter Data” widget. Or perhaps its best use is to just zoom in on a cluster of densely populated points.
Last, hover over and click the small camera icon in the top right-hand corner of the chart area to download a PNG of a plot directly to your browser. This can be handy for sharing findings with colleagues. Or, users are equally welcome to use their favorite screenshot capturing software tools such as the snipping tool / snagit to capture results as well.
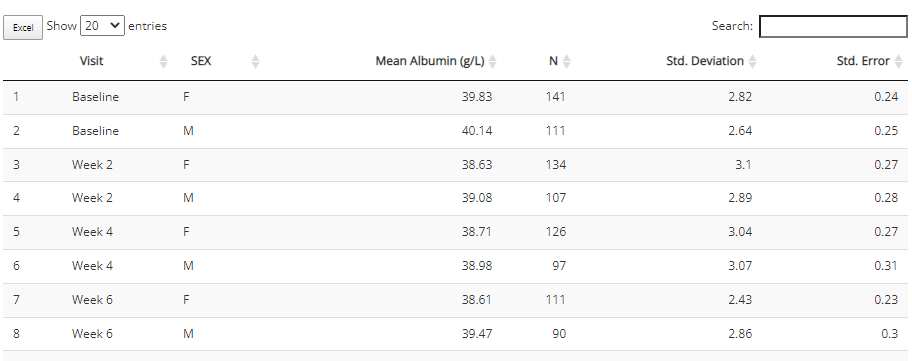
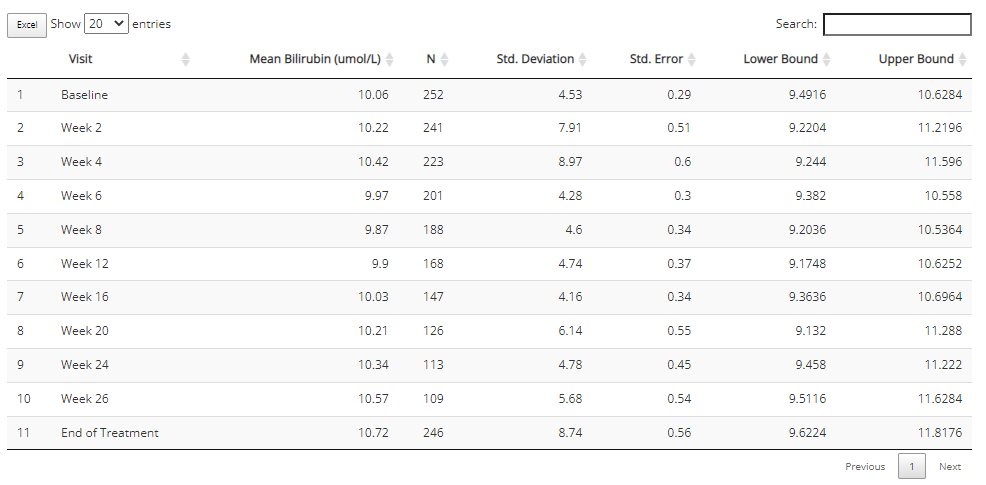
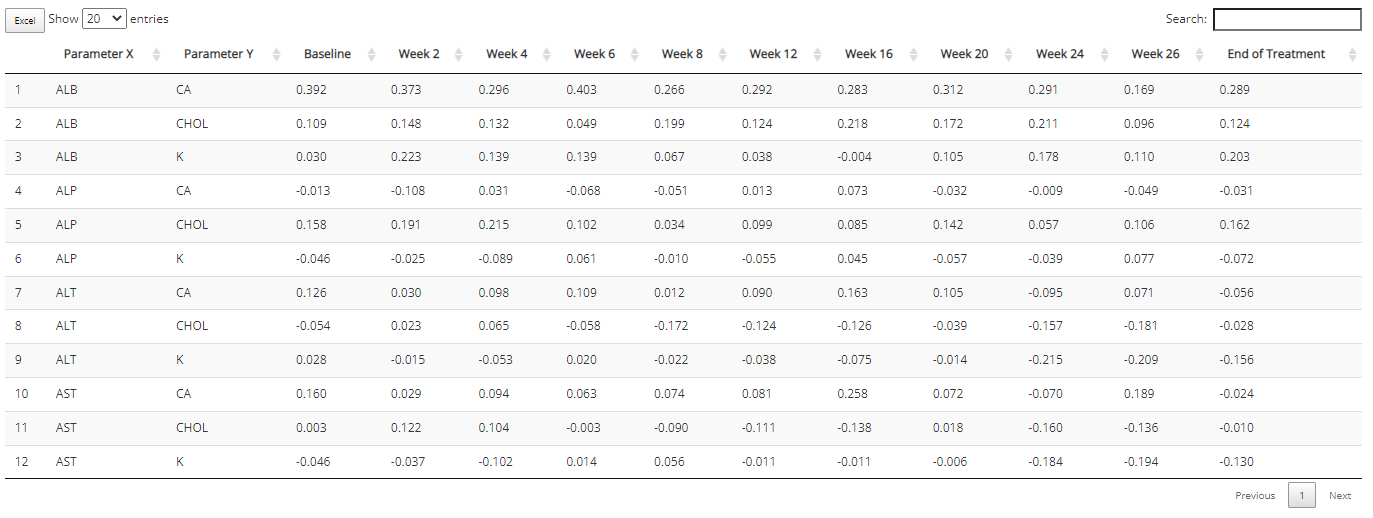
Depending on the chart type, the aggregated data used to build the plot may be included beneath the plot for easy download to Excel. Right now, that includes the “line plot - mean over time” and “Heat map - endpoint correlations”. If desired, select how many rows you’d like to view, search or sort the data, and click the “Excel” button on the top left corner when ready to download.
Now it’s time to dive into each plot and highlight it’s unique output and plot controls.
Scatter plot
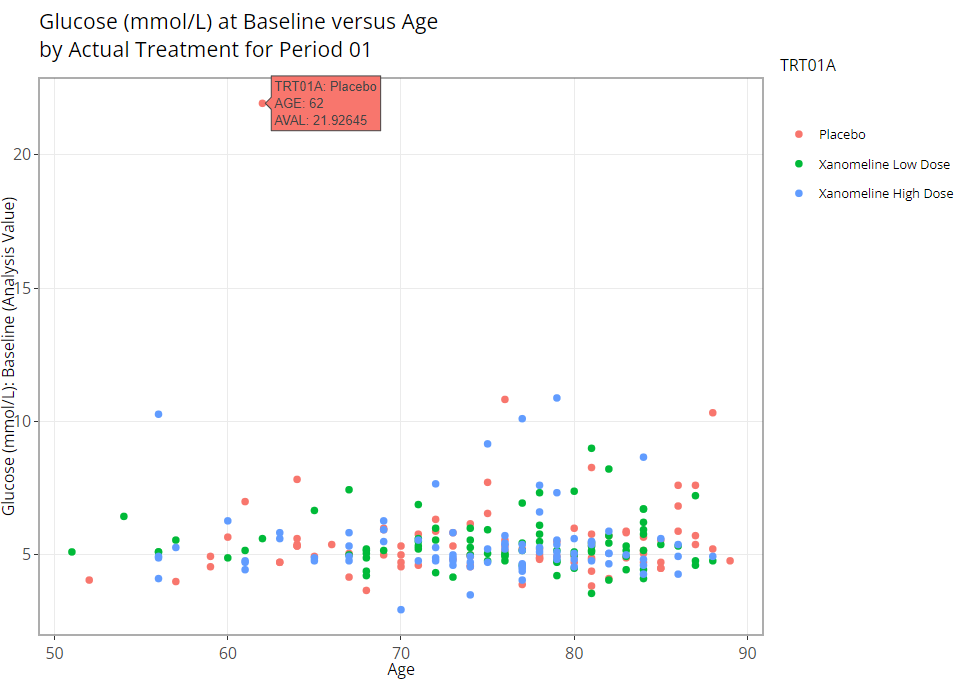
The scatter plot is one of the most basic plots offered by the population explorer. As you’re likely aware, this chart type plots two quantitative variables against each other in a two dimensional space. The plot controls have already been addressed in great detail above. Though it’s a simple graph, it’s output can be quite helpful, especially at identifying outliers since every subject will be plotted on the graph. Here is an example where we can hover over an outlier for more detail when plotting Glucose at baseline vs age.
Spaghetti plot
Similarly, the spaghetti plot mimics the scatter in that every subject is plotted, except the x-axis must be a time variable and a subject’s values are connected with a line. As one might expect, with many subjects, this would lead to a very messy graph. But again, it does allow us to see edge cases very clearly.
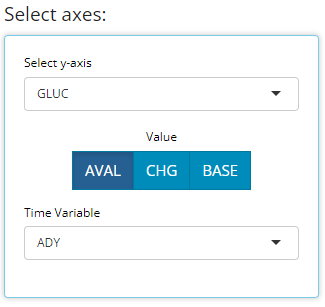
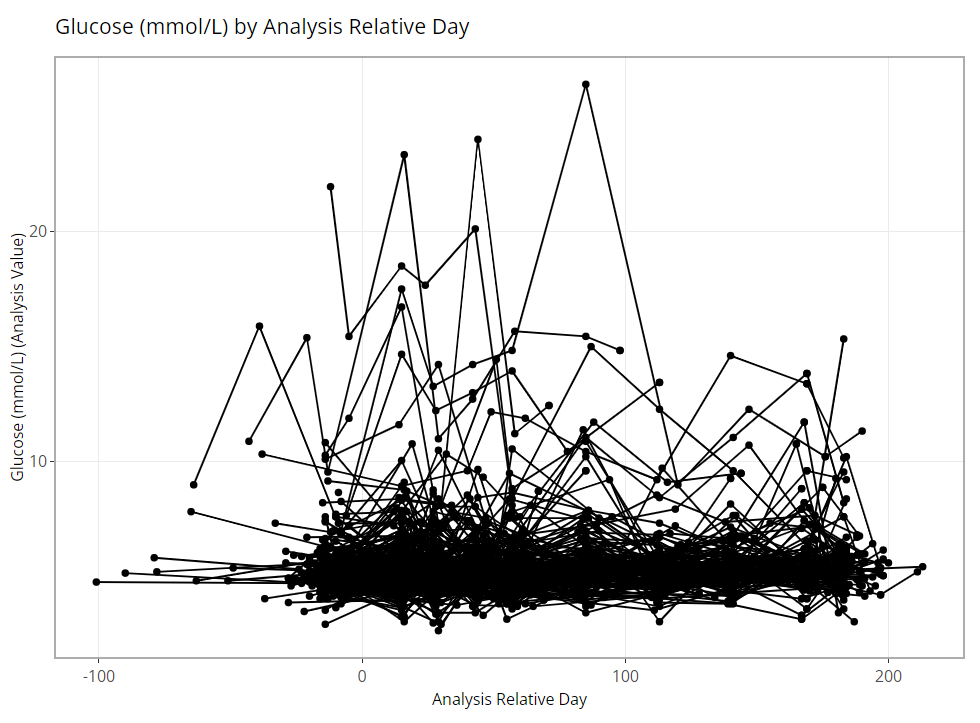
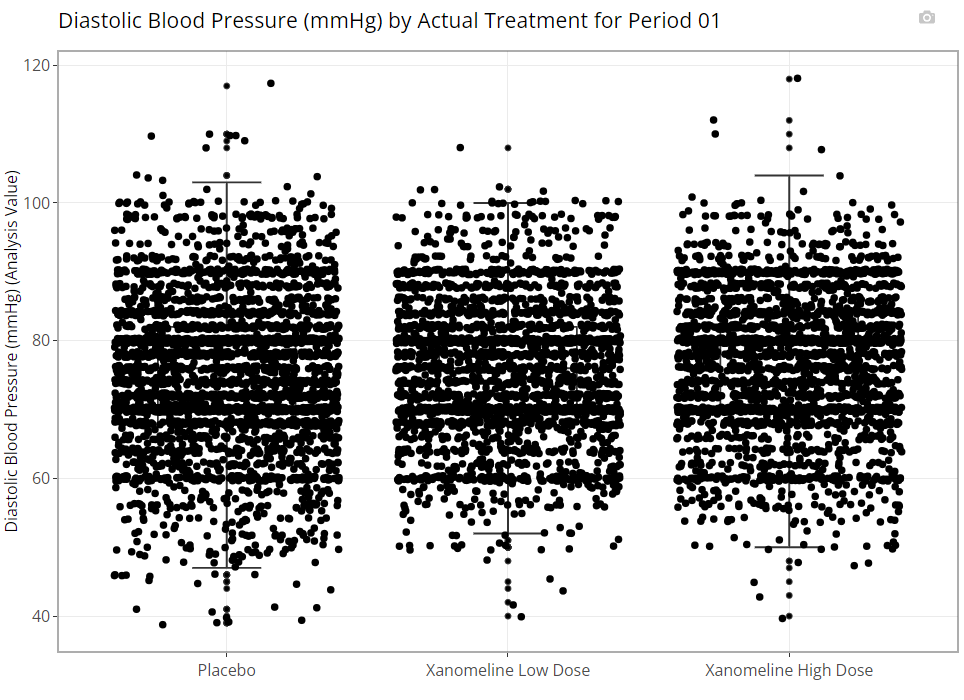
Box Plot
Population Explorer wouldn’t be a legitimate graph generator without a box plot, offering everyone’s favorite 7-number summary on hover. See example below:
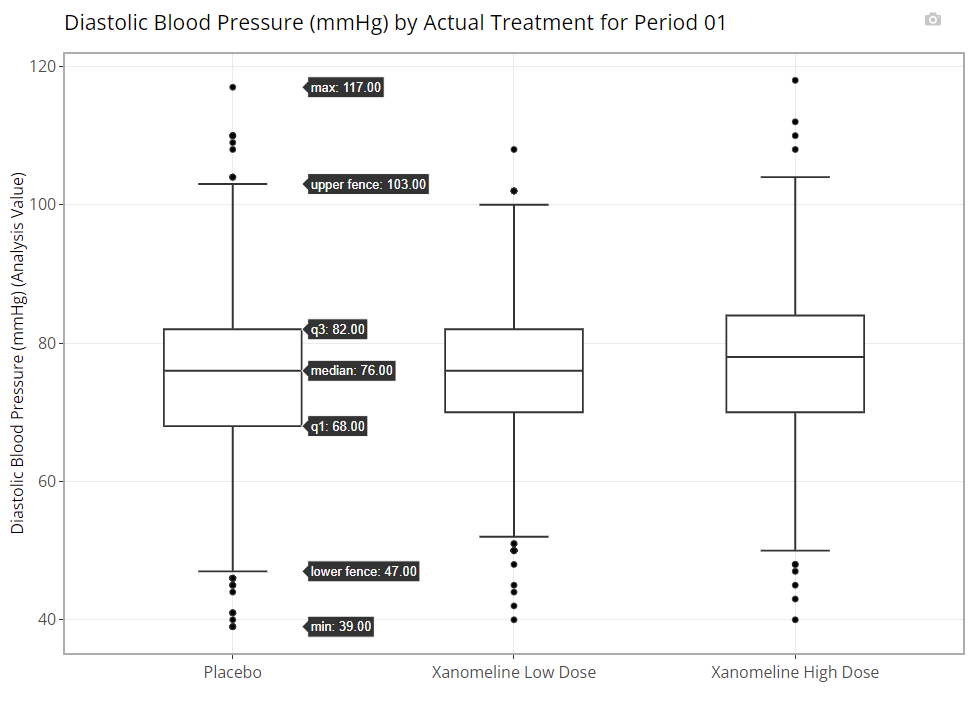
Notice there is an additional plot control called “Add Points?”. If this check box is marked, all individual data points are overlain on the existing box plot in a “jittered” fashion to help the user better understand the distribution of the data.
Line Plot - mean over time
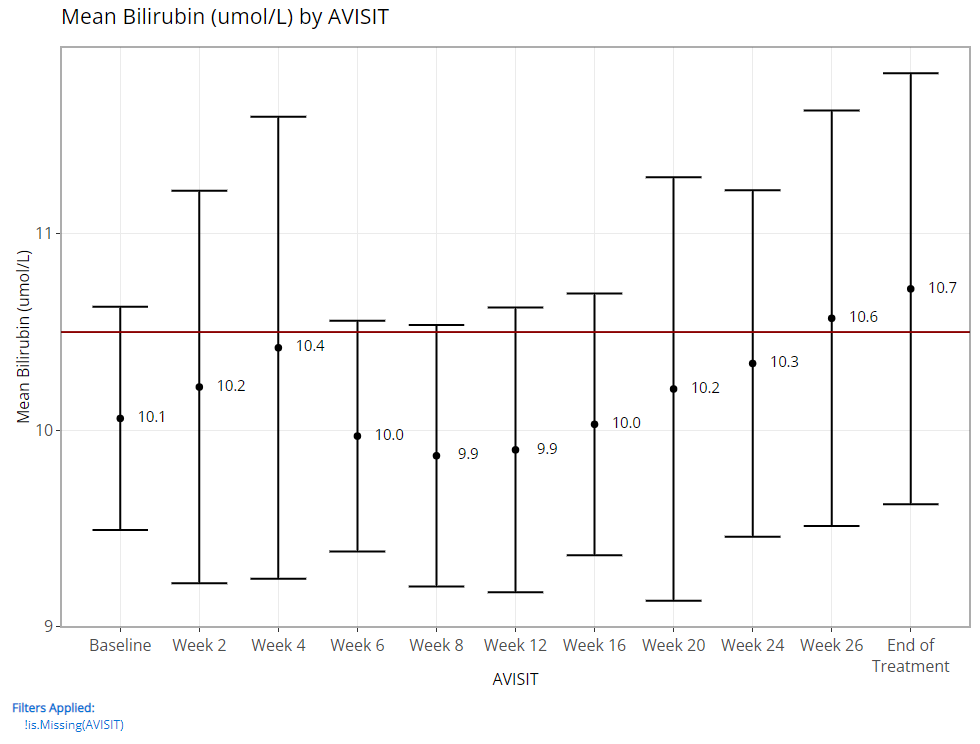
A line plot of mean variables/ parameters over time is a highly leveraged feature of the Population Explorer. As such, there are a few additional custom plot controls that have been engineered for this chart type. Here you can see that in addition to a y-axis and time variable selector, there exist options to overlay a vertical and horizontal line on the plot’s x- or y-axis, respectively. When the feature is toggled on, an addition selector appears to help you set the value. As an example, let’s say we’ve decided that 10.5 is an important bilirubin value we want to compare against and if the average extends above this threshold, we want that to be visually obvious. So, overlaying a horizontal line at 10.5 is a great value add for this plot.
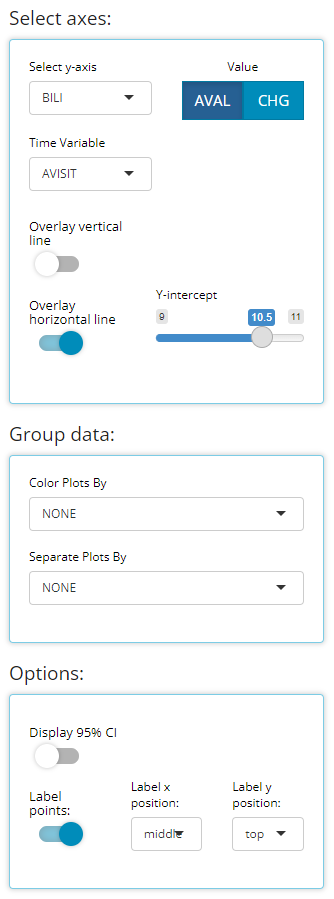
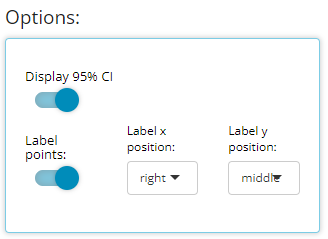
We’ve discussed the “Group Data” plot controls above, so we’ll choose to bypass those for now. However, we have chosen to label our plotted data points below. This toggle simply turns the feature on/off plus allows us to position the labels in the most visible location. For this example, on top and centered data labels are extremely visible and produces the following output:
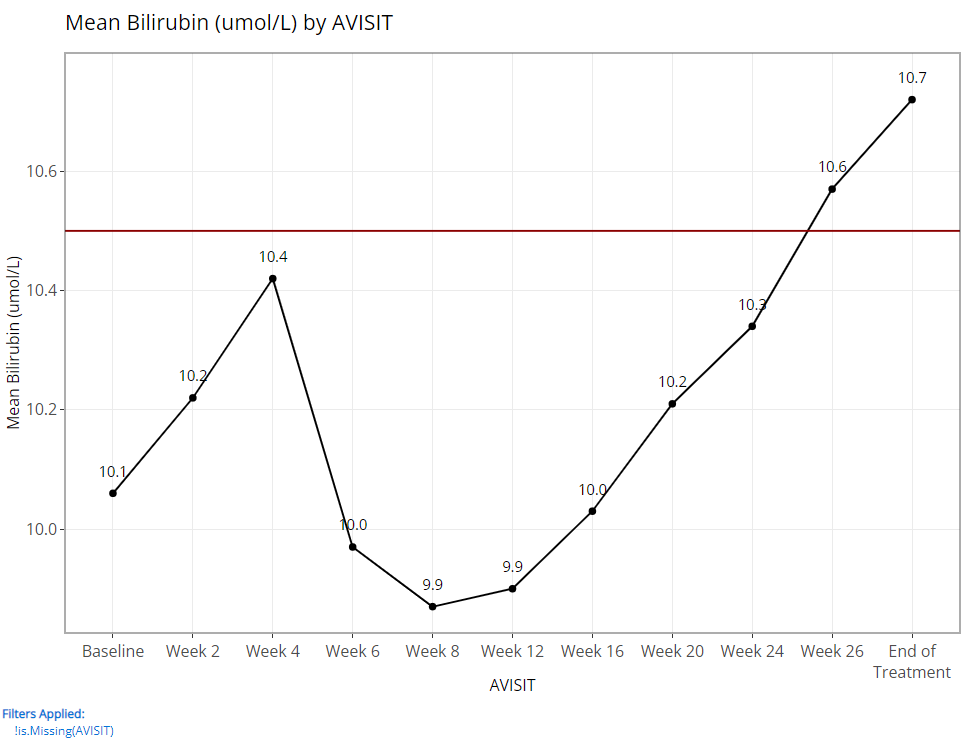
And if we choose to display 95% confidence intervals for each mean, we need only toggle a few options as follows to produce the following output:
Notice that this chart type offers a view of the aggregated plot data. If you wish to download it from the browser, simply click the “Excel” button.
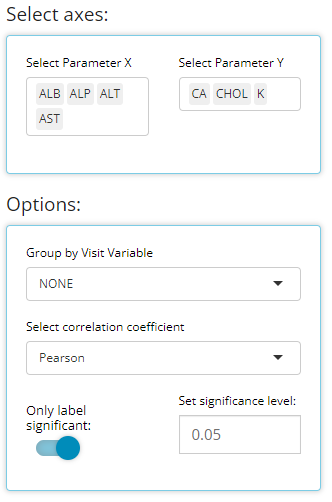
Heatmap - endpoint correlations
Certain analyses require to check if parameters / endpoints are highly correlated with each other. This heat map chart helps us to do that quickly and with ease. First, the user can select any number of parameters for the x-axis and y-axis using the “Select axes” drop down lists. Doing so will generate a pair-wise grid shaded according to the correlation coefficient of your choice: either pearson (the default) or (Spearmans). Here, we’ve requested to only label significant correlations with alpha = 0.05.
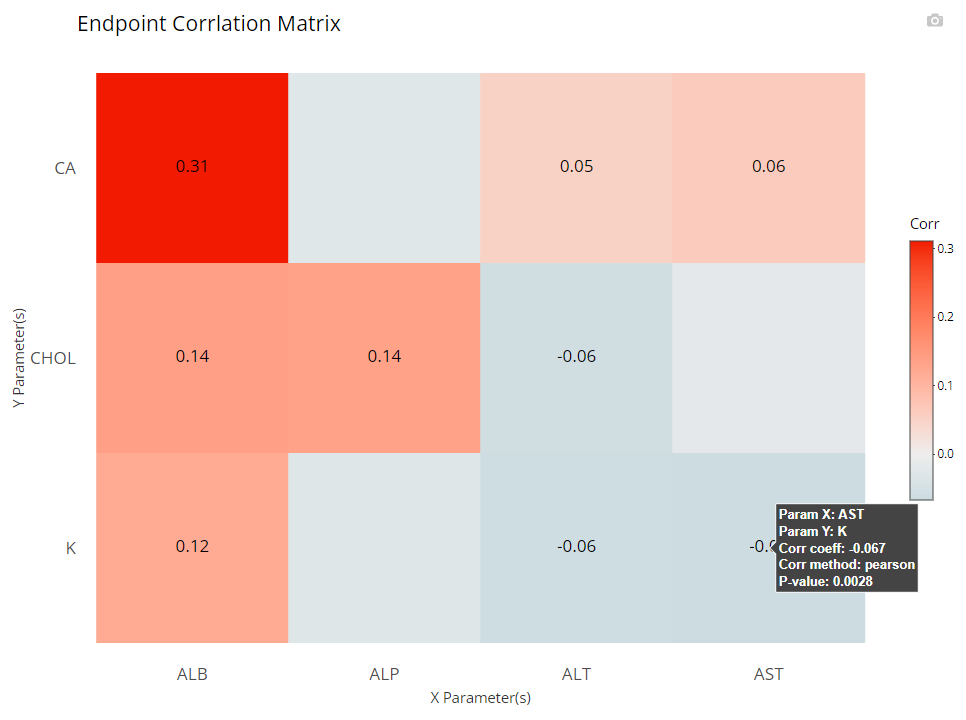
Again, it’s important to note that the color gradient in the graph is calibrated to the highest correlation coefficient calculated out of the bunch. When hovered over, you can view all the needed details, including exact p-values.
Furthermore, you may want to check your endpoint correlations from week-to-week. So with all other options remaining the same, if we choose ‘AVISIT’ as a grouping variable, the following plot is rendered:
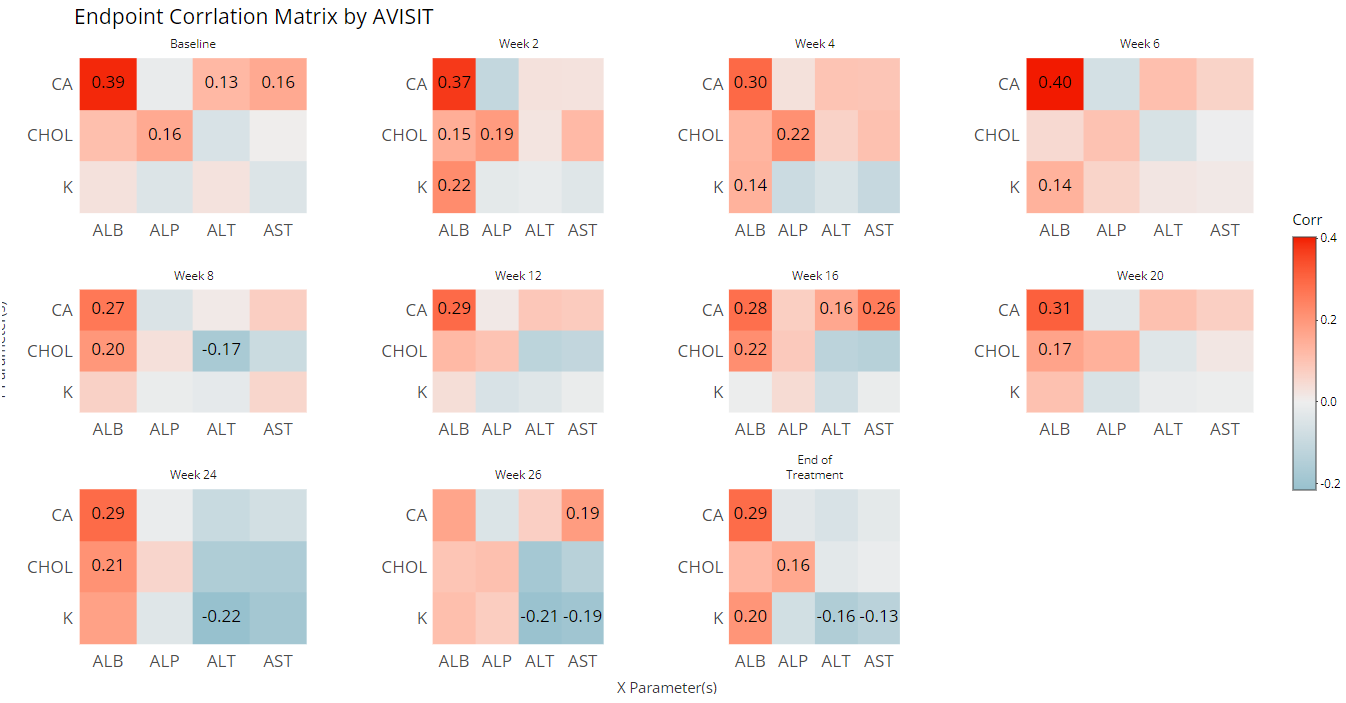
That’s a lot of information / data to consume visually, so an export to Excel is available below the plot:
Kaplan-Meier Curve
Any time-to-event (TTE) analysis will include an
obligatory Kaplan-Meier curve. And rightfully so! Much information can
be gleaned from these graphics. The x-axis always contains a measure of
time and the y-axis contains the probability of “surviving” up till or
past those times. In the case of the CDISC Pilot data, we’re measuring
the probability of a patient having their first dermatological event for
each time value, x. So even though the y-axis is labeled, “survival”,
don’t think of it in terms of life or death! For any point on the graph,
you can interpret plotted values as: “The probability of a patient
having their first dermatological event on or past X time units, is
Y.”
tidyCDISC knows which data sources contain
TTE data based on the presence of the CDISC required
CNSR variable. The CNSR variable must be
either a 0 or 1. Zero indicates the patient’s survival status is unknown
after time period X. That is, we only have some
information about the patient’s time-to-event survival up to a certain
point, X, but after that time, their survival is unknown. Instead of
just throwing away that data, it’s valuable to know that they made it to
at least time X. That time point data is retained and their last known X
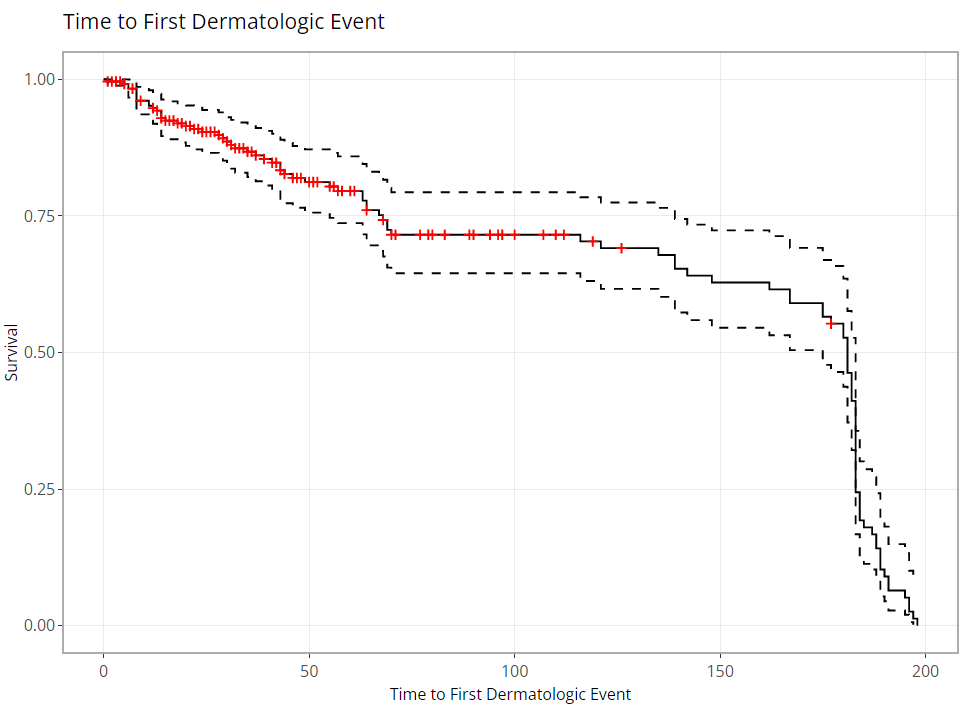
value is marked with a red “+” in the plot below.
In the plot control panel, we can toggle the TTE
parameter, the response value (like AVAL), and even the
censor variable if case your data source has more than one. We’ve chosen
to mark our censored observations and show 95% confidence bands in the
below graphic:
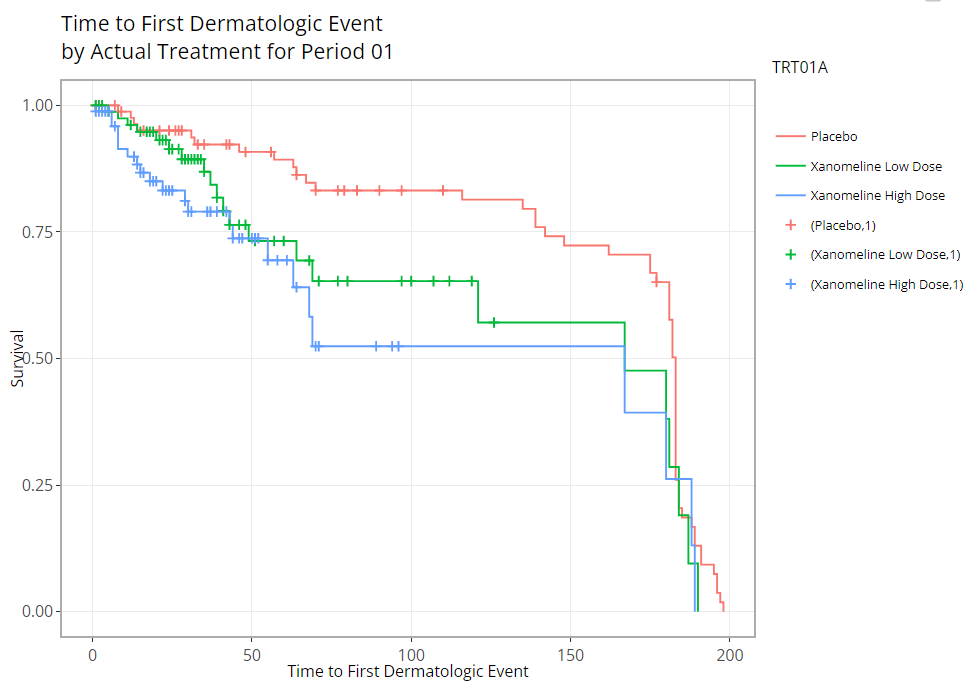
As you might expect, these plots can be extremely handy, and remarkably powerful when comparing time-to-event probability between groups of patients. Making a few adjustments to our options produces the following plot, which reveals differences between treatment groups. PRO-TIP: If you’re interested in seeing if the probably of survival is significantly different between groups, you need only turn on the 95% confidence bands and look for any instance where the bands do not intersect.
Filtering
Like other tidyCDISC tabs, the “Filter Data” widget
manipulates the data before it is processed on the tab, in this case:
plotted. Filtering will not be discussed in detail guide so you’re
highly encouraged to view the article called 04
Filtering for a complete filtering tutorial. However, we will
address a few things that are unique about filtering in the Population
Explorer. By clicking the drop down arrow, the filtering widget expands
to reveal the following controls:
First, this is the only tab that has an “Apply Filters” toggle that precedes the usual ADaM data selector and “Add Filter” button. This toggle provides unique functionality when plotting, giving the user the following luxuries:
Build filters all at once. If the user has many filters to define on variables from multiple data sources, the chart will continually re-render after each filter is added. With large data sets, this can lead to a user experience that is somewhat slow and sluggish. As such, its advised to define your filters on the front end and then toggle “Apply Filters” to the “on” position to save time and compute power. Below is an example workflow displaying this practice.
Switch back and forth between filtered and un-filtered versions of the plot. This can be useful to verify expected changes in the plot before and after filtering.
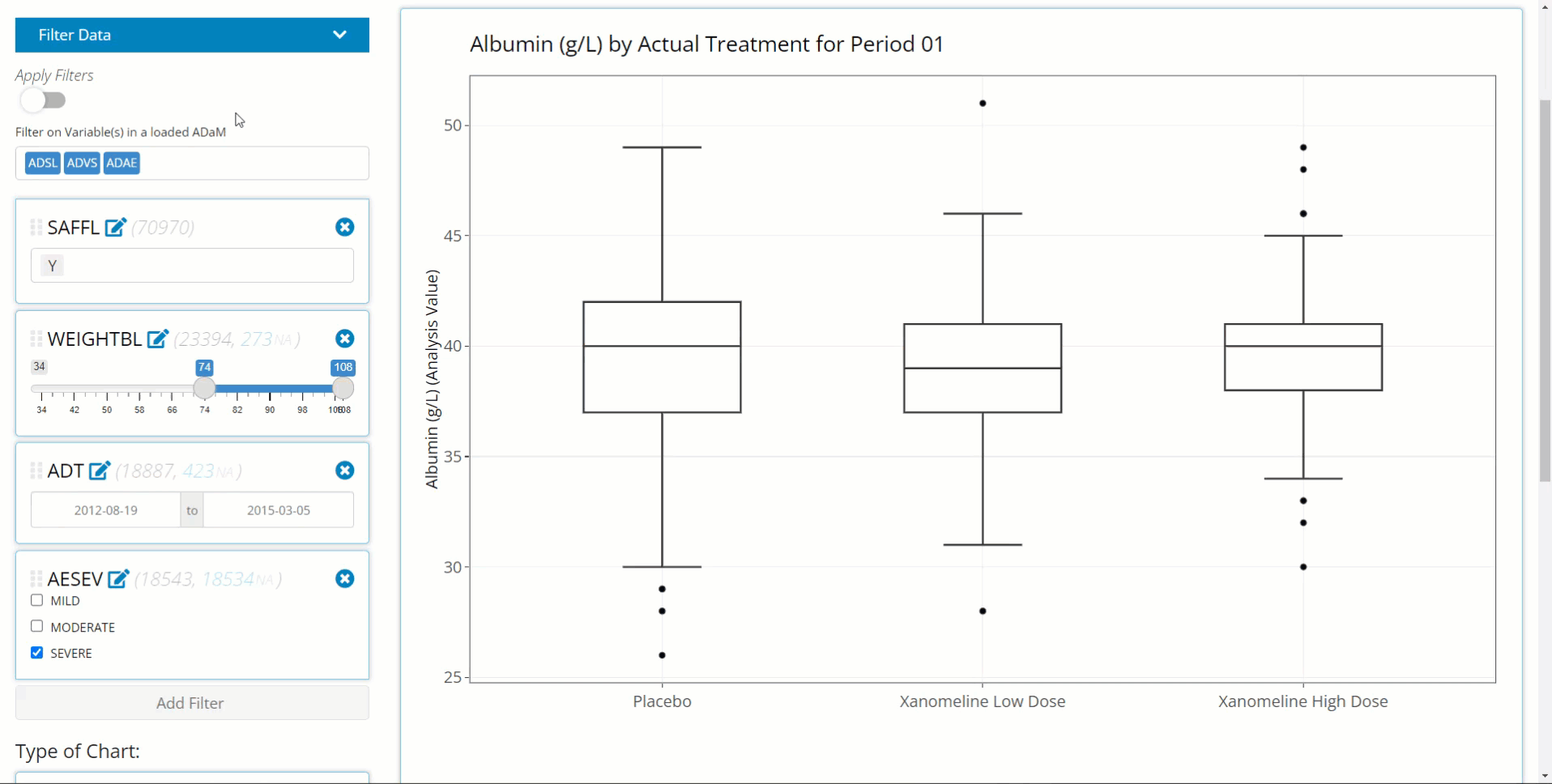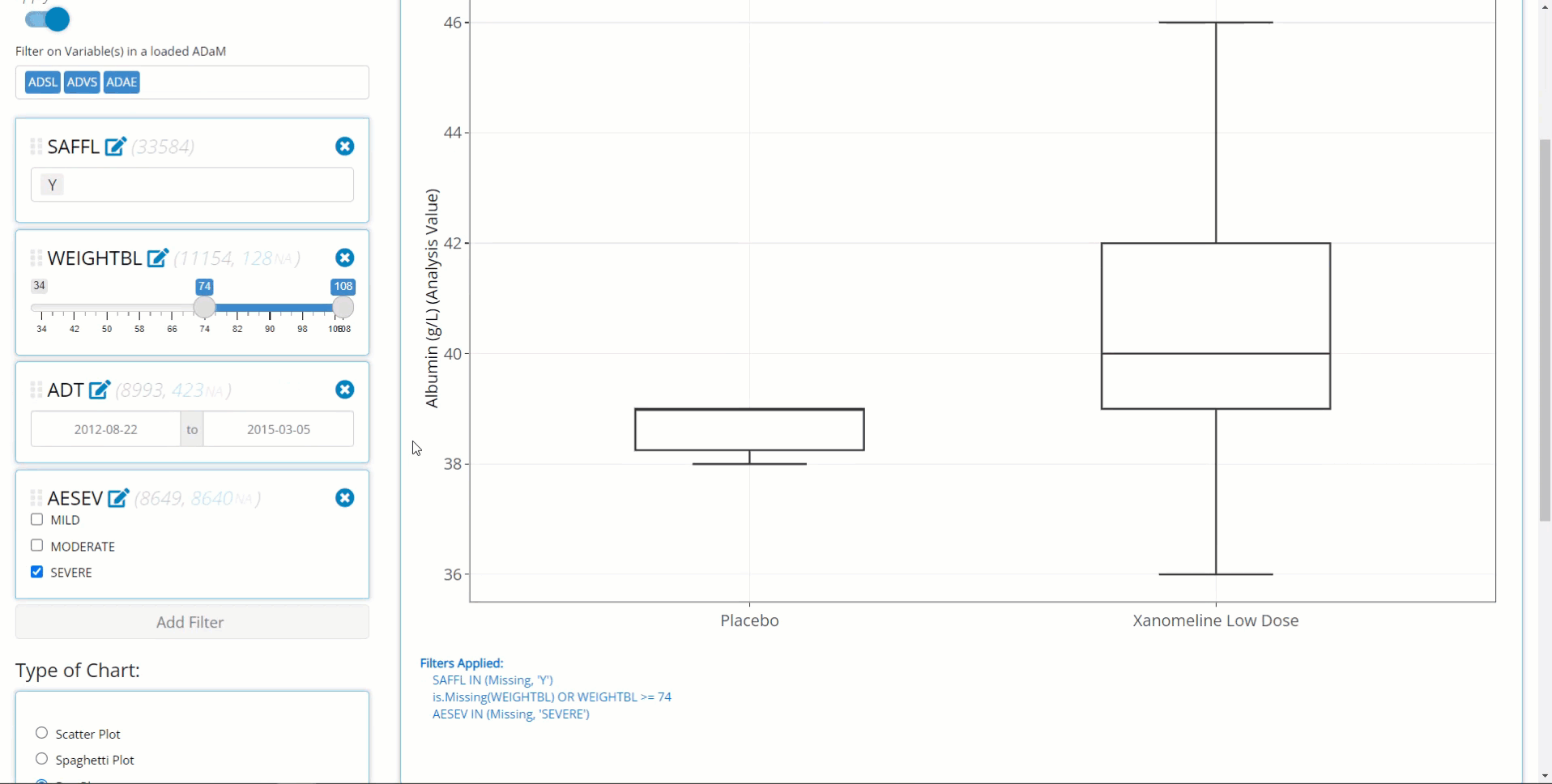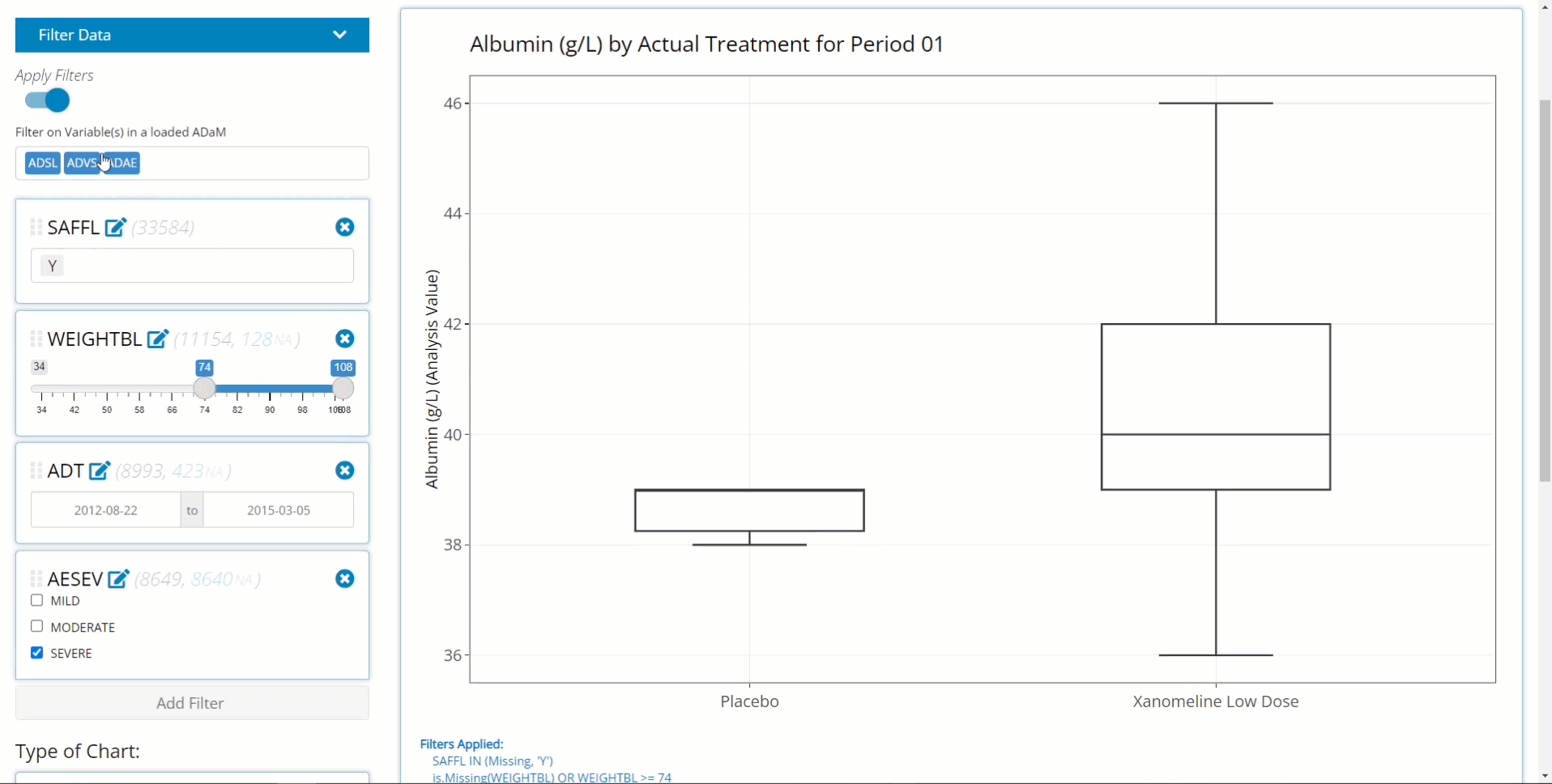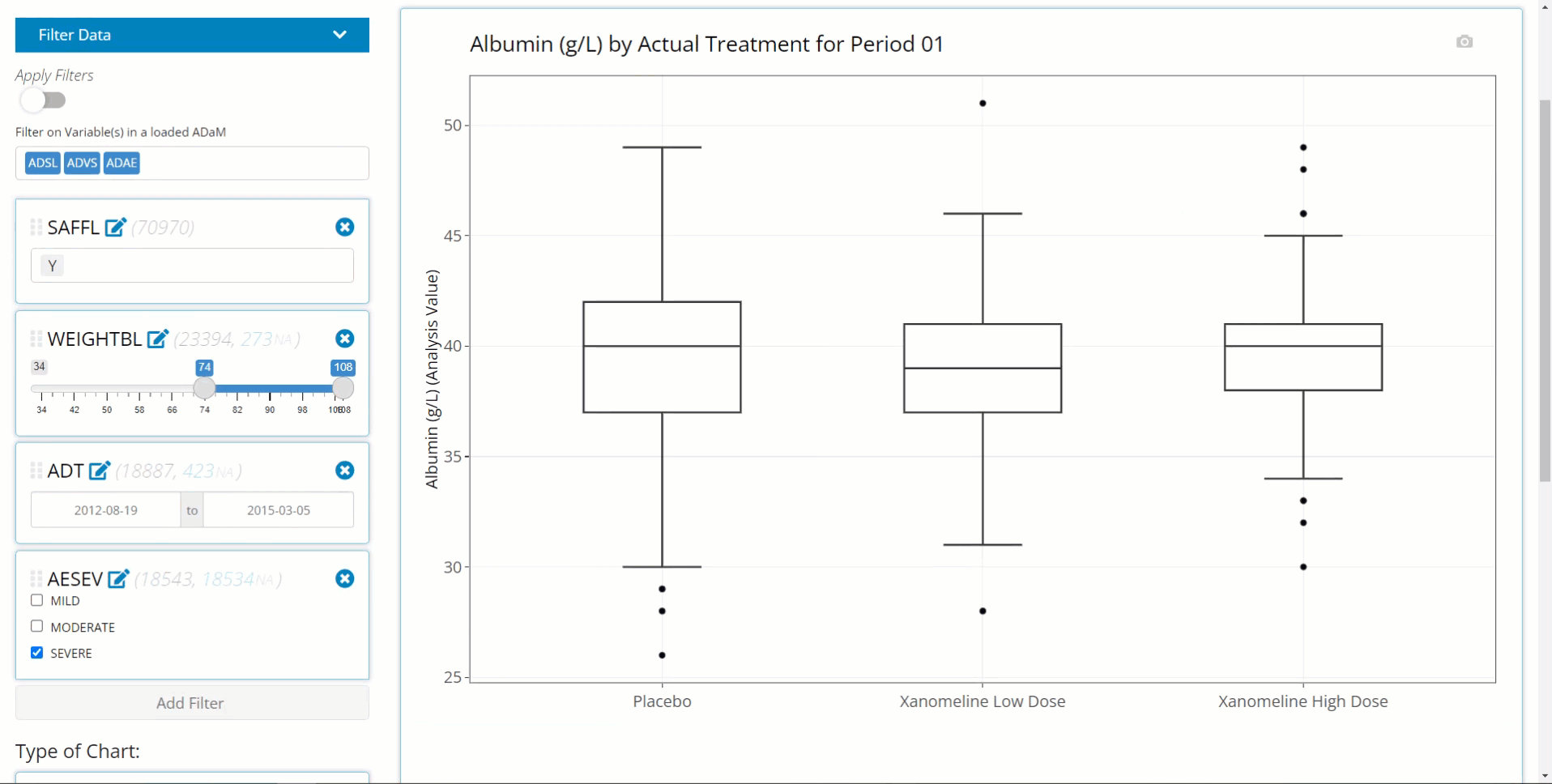
Second, notice that the the text describing the filtering appears below the chart on the left-hand side.
Need help?
Throughout all the tabs in the application, there are these little buttons (usually in the top right-hand corners) with question marks on them:

When clicked, they launch a real-time guide that walks the user through the major components of the currently visible screen/ tab, providing context and suggested workflow. However, if the in-app guide doesn’t address your needs, consult the online documentation (that you’re reading now) for the most thorough user guide. If all else fails, send the developers an message with your question or request!